Update 05/21/2013 – The code for the python script that allows you to mass download Nessus reports can be found here. Also, here’s a post detailing a little bit about that script.
I recently started looking into the Nessus API Documentation and found that that you could interact with Nessus and get almost ALL of the features of the GUI via HTTP POST’s and GET’s. You just needed to be able to parse out the XML responses. Awesome!
If you look int API docs you’ll see it’s really straightforward; you can use tools like wget or curl to send the HTTP requests, then you can parse the XML response to pull the data you need. I use xmlstarlet (just use apt-get install xmlstarlet in Ubuntu) as my parser.
Let’s start working with Nessus via curl. First step, get logged in:
curl -k -c cookies.txt --data "login=YOURUSERNAME&password=YOURPASSWORD" https://127.0.0.1:8834/login
Here we’re ignoring SSL cert check (-k) and saving the cookies that are set are sent to a file for later use (-c cookies.txt). Then we send the post parameters “login” and “password” to the “/login” page of our local Nessus scanner. If you put in your username and password correctly you’ll see an “OK” response and a session cookie is saved to cookies.txt.
Now we can re-use that cookie in later requests without having to re-authenticate. I try to avoid hard coding passwords in scripts, it’s a bad practice.
NOTE: the Nessus config value “xmlrpc_idle_session_timeout” is set to 30 by default, so you can use that cookie for 30 minutes.
Now let’s list all of the available reports on our scanner and see the raw XML output:
curl -k -b cookies.txt https://127.0.0.1:8834/report/list
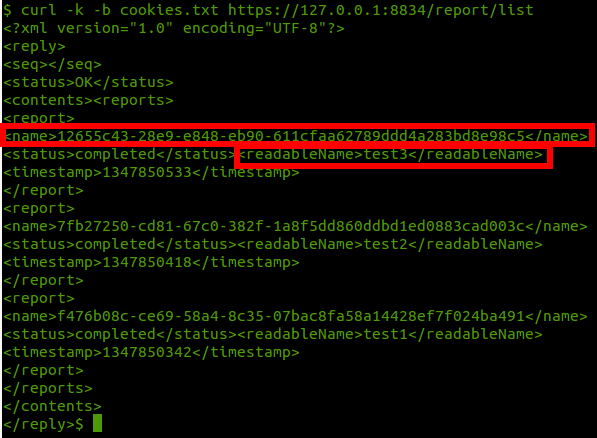
Above you’ll see I highlighted the “name” and the “readableName” node’s in the XML response. The name is the UUID. You’ll need to reference this when interacting with scansreports via xml-rpc. The readableName is obviously the name you typed into the scanner when running the scan.
Now let’s make more sense of the XML response by using xmlstarlet to parsepull the relevant fields out. NOTE: XML parsing and using XPATH queries are beyond the scope of this post. If you’ve never used XPATH queries it’s simply a query syntax used when dealing with XML data and it’s hierarchical format of trees and nodes.
curl -k -b cookies.txt https://127.0.0.1:8834/report/list | xmlstarlet sel -B -t -m "reply/contents/reports/report/name" -v "." -o ": " -v "../readableName" -n
![]()
I output the UUID and the readable name next to each other (Click on picture above for a better view).
Now let’s get a list of running scans, and then pause all of them. Notice the URL that i send requests to via curl has changed. Now I’m interacting with scans, rather than reports.
curl -k -b cookies.txt https://127.0.0.1:8834/scan/list|xmlstarlet sel -B -t -m "reply/contents/scans/scanList/scan/status" -o "UUID: " -v "../uuid" -o " Readable Name:" -v "../readableName" -o " Status:" -v "." -n|grep running
![]()
You see I output the UUID, readable name and the scan status. Now we’ll use a simple for loop and send the UUID of each scan that is running as a paramater to the /scan/pause page to pause the scans.
for scan in $(curl -k -b cookies.txt https://127.0.0.1:8834/scan/list|xmlstarlet sel -B -t -m "reply/contents/scans/scanList/scan/status" -o "UUID: " -v "../uuid" -o " Readable Name:" -v "../readableName" -o " Status:" -v "." -n|grep running|cut -d" " -f2); do curl -k -b cookies.txt --data "scan_uuid=$scan" https://127.0.0.1:8834/scan/pause;done
If you log in to your scanner now you’ll see the scan names you grepped for and paused above are indeed paused.
I hope that’s given you an idea of how you can use XML RPC to customizecontrol your Nessus experience.
